
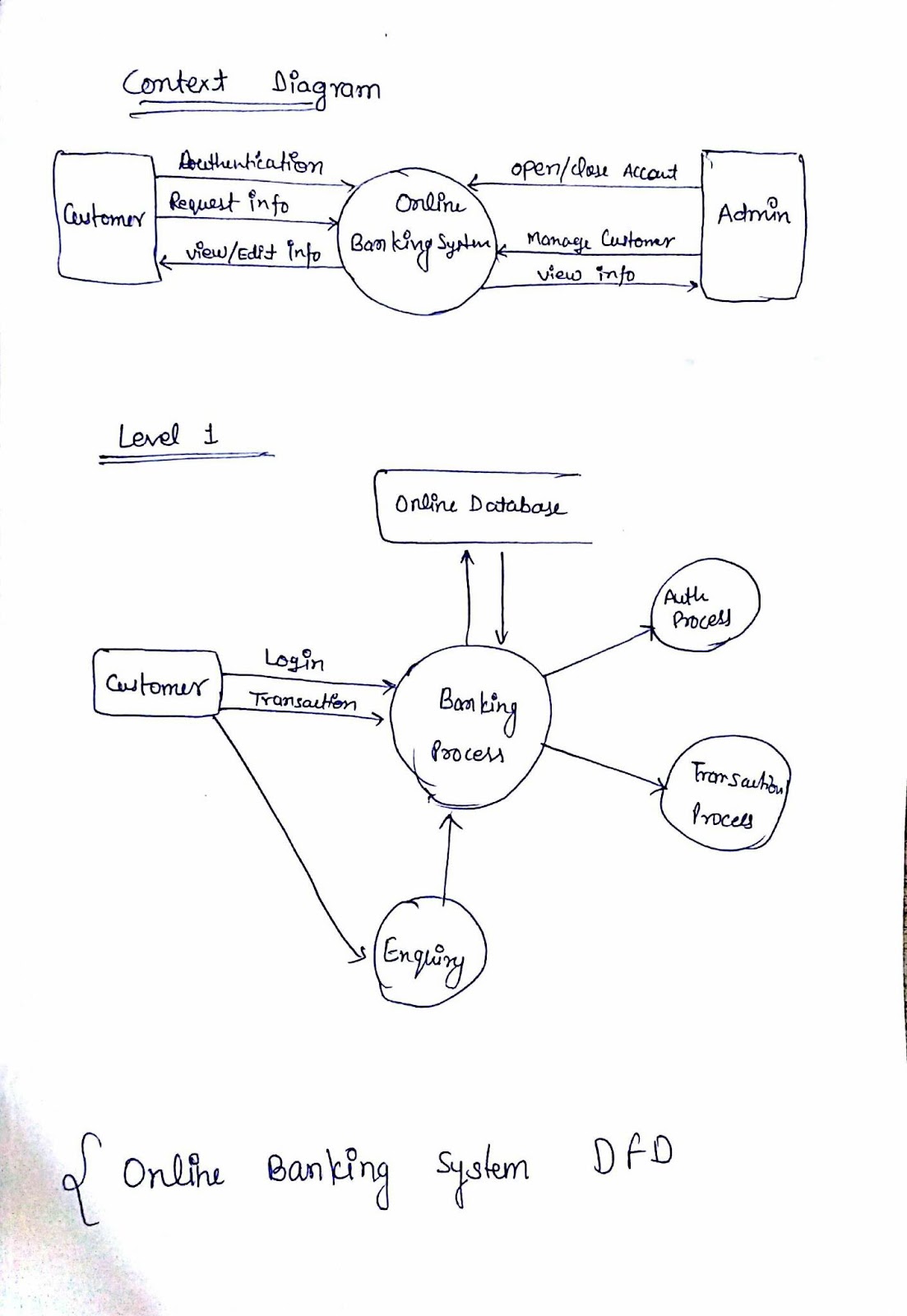
 |
| http://www.conceptdraw.com/ |

Verify the expression n! = O(n^n)
Heap Complexity
The part just shown very similar to removal from a heap which is O(log(n)). You do it n-1 times so it is O(nlog(n)). The last steps are cheaper but for the reverse reason from the building of the heap, most are log(n) so it is O(nlog(n)) overall for this part. The build part was O(n) so it does not dominate. For the whole heap sort you get O(nlog(n)).There is no extra memory except a few for local temporaries.
Thus, we have finally achieved a comparison sort that uses no extra memory and is O(nlog(n)) in the worst case.
In many cases people still use quick sort because it uses no extra memory and is usually O(nlog(n)). Quick sort runs faster than heap sort in practice. The worst case of O(n2) is not seen in practice.
Complexity Analysis of Bubble Sorting
In Bubble Sort, n-1 comparisons will be done in 1st pass, n-2 in 2nd pass, n-3 in 3rd pass and so on. So the total number of comparisons will be
(n-1)+(n-2)+(n-3)+.....+3+2+1
Sum = n(n-1)/2
i.e O(n2)
Hence the complexity of Bubble Sort is O(n2).The main advantage of Bubble Sort is the simplicity of the algorithm.Space complexity for Bubble Sort is O(1), because only single additional memory space is required for temp variable
Best-case Time Complexity will be O(n), it is when the list is already sorted.

We assume that we're sorting a total of
- The divide step takes constant time, regardless of the subarray size. After all, the divide step just computes the midpoint
of the indicesand. Recall that in big-Θ notation, we indicate constant time by. - The conquer step, where we recursively sort two subarrays of approximately
elements each, takes some amount of time, but we'll account for that time when we consider the subproblems. - The combine step merges a total of
elements, takingtime.
If we think about the divide and combine steps together, the
Let's draw out the merging times in a "tree":
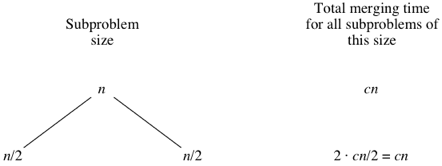
Computer scientists draw trees upside-down from how actual trees grow. Atree is a graph with no cycles (paths that start and end at the same place). Convention is to call the vertices in a tree its nodes. The root node is on top; here, the root is labeled with the
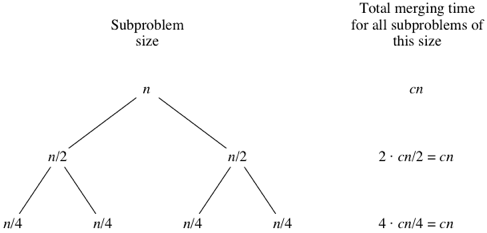
What do you think would happen for the subproblems of size
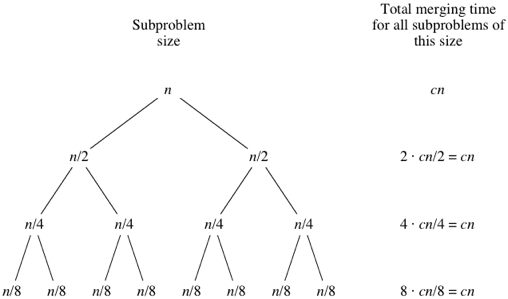
As the subproblems get smaller, the number of subproblems doubles at each "level" of the recursion, but the merging time halves. The doubling and halving cancel each other out, and so the total merging time is
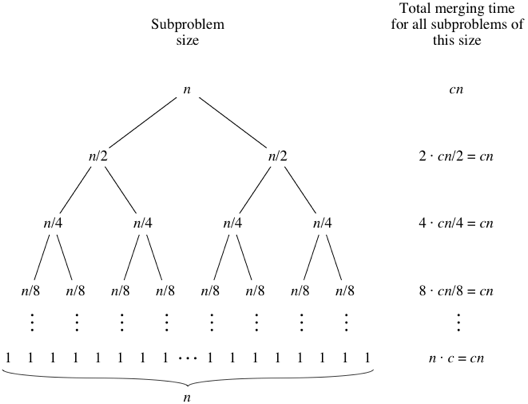
When we use big-Θ notation to describe this running time, we can discard the low-order term (
Read more from Source: https://www.khanacademy.org/computing/computer-science/algorithms/merge-sort/a/analysis-of-merge-sort
