Standard ContainersA container is a holder object that stores a collection of other objects (its elements). They are implemented as class templates, which allows a great flexibility in the types supported as elements.
The container manages the storage space for its elements and provides member functions to access them, either directly or through iterators (reference objects with similar properties to pointers).
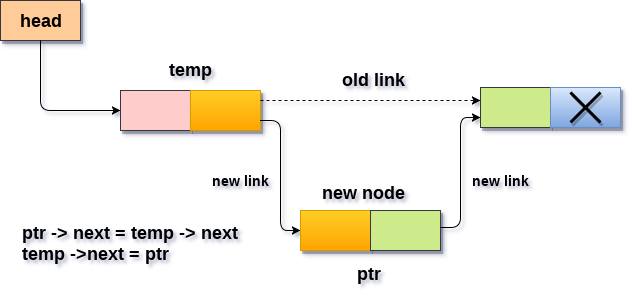
Containers replicate structures very commonly used in programming: dynamic arrays (vector), queues (queue), stacks (stack), heaps (priority_queue), linked lists (list), trees (set), associative arrays (map)…
Many containers have several member functions in common, and share functionalities. The decision of which type of container to use for a specific need does not generally depend only on the functionality offered by the container, but also on the efficiency of some of its members (complexity). This is especially true for sequence containers, which offer different trade-offs in complexity between inserting/removing elements and accessing them.
stack, queue and priority_queue are implemented as container adaptors. Container adaptors are not full container classes, but classes that provide a specific interface relying on an object of one of the container classes (such as deque or list) to handle the elements. The underlying container is encapsulated in such a way that its elements are accessed by the members of the container adaptor independently of the underlying container class used.
Container class templates
Sequence containers:
array Array class (class template )vectorVector (class template )dequeDouble ended queue (class template )forward_list Forward list (class template )listList (class template )
Container adaptors:
stackLIFO stack (class template )queueFIFO queue (class template )priority_queuePriority queue (class template )
Associative containers:
setSet (class template )multisetMultiple-key set (class template )mapMap (class template )multimapMultiple-key map (class template )
Unordered associative containers:
unordered_set Unordered Set (class template )unordered_multiset Unordered Multiset (class template )unordered_map Unordered Map (class template )unordered_multimap Unordered Multimap (class template )
Other:
Two class templates share certain properties with containers, and are sometimes classified with them: bitset and valarray.
Member map
This is a comparison chart with the different member functions present on each of the different containers:
Legend:
| C++98 | Available since C++98 |
|---|---|
| C++11 | New in C++11 |